딥러닝 뜻 정리, 딥러닝이란 무엇이고 왜 중요한가?

요즘 인공지능 이야기를 하다 보면 빠지지 않고 등장하는 단어가 바로 딥러닝입니다. 뉴스, 유튜브, IT 기사에서 하루에도 몇 번씩 보게 되지만, 막상 “딥러닝이 정확히 뭐냐”고 물으면 설명하기가 쉽지 않습니다.
저 역시 처음에는 머신러닝이랑 뭐가 다른지, 그냥 어려운 인공지능 기술 정도로만 이해하고 있었습니다. 그래서 이번 글에서는 딥러닝 뜻, 그리고 딥러닝이란 무엇인지를 최대한 쉽게 정리해보려고 합니다.
딥러닝이란 무엇인가?
딥러닝(Deep Learning)은 인공지능의 한 분야로, 인간의 뇌 구조를 본떠 만든 **인공신경망(Neural Network)**을 여러 층으로 깊게 쌓아 학습시키는 기술을 말합니다.
여기서 ‘딥(Deep)’이라는 표현은 신경망의 층(layer)이 많다는 의미에서 나온 말입니다.
쉽게 말해 딥러닝은
👉 컴퓨터가 스스로 특징을 찾아내며 학습하는 방식이라고 이해하면 됩니다.
과거에는 사람이 “이건 고양이의 귀, 이건 눈”처럼 기준을 직접 알려줘야 했다면, 딥러닝은 수많은 데이터를 보면서 컴퓨터가 스스로 패턴을 찾아냅니다.

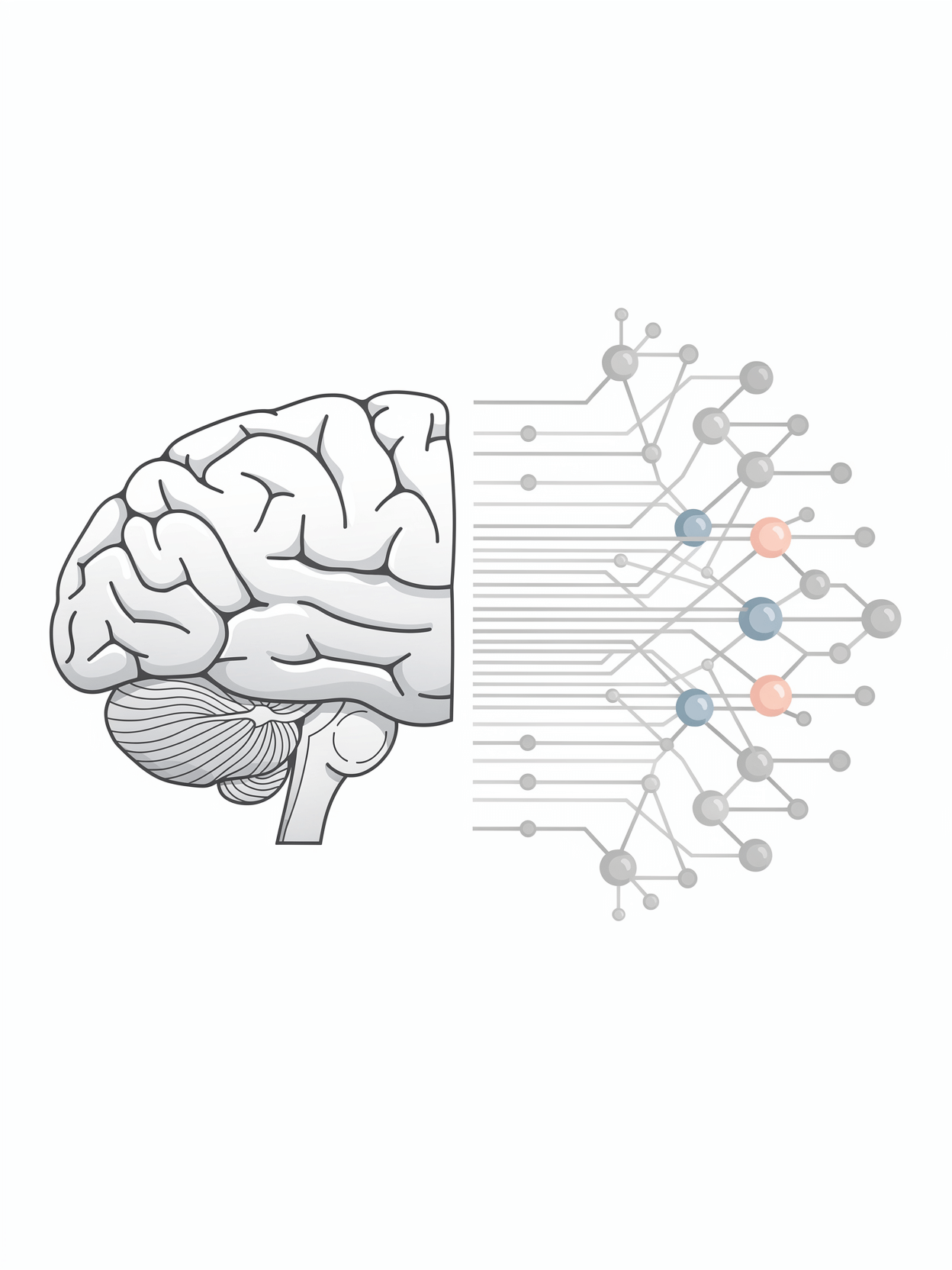
딥러닝과 머신러닝의 차이
딥러닝은 머신러닝의 한 종류입니다.
다만 두 개념에는 분명한 차이가 있습니다.
- 머신러닝: 사람이 중요한 특징을 어느 정도 정리해주고, 그걸 바탕으로 학습
- 딥러닝: 특징 추출부터 판단까지 모두 모델이 스스로 학습
예를 들어 사진 인식에서
머신러닝은 “눈, 코, 입” 같은 정보를 사람이 먼저 정의해야 했다면,
딥러닝은 픽셀 데이터만 보고도 스스로 고양이인지 사람인지 구분하는 단계까지 도달합니다.
이 차이 때문에 데이터가 많을수록 딥러닝의 성능이 폭발적으로 좋아집니다.

딥러닝은 어떻게 학습할까?
딥러닝의 핵심 구조는 입력층 → 여러 개의 은닉층 → 출력층입니다.
- 입력층: 이미지, 소리, 문자 같은 원본 데이터
- 은닉층: 데이터를 단계적으로 분석하며 특징을 추출
- 출력층: 최종 판단 결과 도출
학습 과정에서는 정답과 예측값의 차이를 계산하고, 그 오차를 줄이는 방향으로 신경망의 가중치를 계속 수정합니다. 이 과정을 수천, 수만 번 반복하면서 점점 정확도가 높아집니다.
그래서 딥러닝에는 **많은 데이터와 강력한 연산 능력(GPU)**이 필수적으로 따라옵니다.



딥러닝이 사용되는 분야
딥러닝은 이미 우리 일상 곳곳에 사용되고 있습니다.
- 이미지 인식: 얼굴 인식, CCTV 분석, 의료 영상 판독
- 음성 인식: 음성 비서, 자동 자막, 통화 녹취 분석
- 자연어 처리: 번역, 챗봇, 검색 알고리즘
- 자율주행: 도로 인식, 객체 감지, 판단 시스템
- 추천 시스템: 유튜브, 넷플릭스, 쇼핑몰 추천
특히 사람이 규칙을 일일이 정의하기 어려운 영역에서 딥러닝의 강점이 극대화됩니다.

딥러닝의 장점과 한계
장점
- 복잡한 패턴 인식에 매우 강함
- 데이터가 많을수록 성능 향상
- 사람이 개입하지 않아도 스스로 학습 가능
한계
- 많은 데이터와 연산 자원이 필요
- 결과가 왜 그렇게 나왔는지 설명하기 어려움(블랙박스 문제)
- 잘못된 데이터로 학습하면 오류도 그대로 커짐
그래서 딥러닝은 “만능 기술”이라기보다, 잘 쓰면 강력하지만 관리가 중요한 도구에 가깝습니다.



요약 정리
딥러닝은 인공신경망을 기반으로 한 인공지능 기술입니다.
스스로 특징을 학습하는 것이 가장 큰 특징입니다.
머신러닝보다 구조가 깊고 데이터 의존도가 높습니다.
이미 우리 일상 속 다양한 기술에 활용되고 있습니다.



마무리하며
딥러닝을 이해하고 나니, 왜 요즘 인공지능 발전 속도가 이렇게 빠른지 조금은 감이 잡혔습니다. 결국 딥러닝은 컴퓨터가 인간의 학습 방식을 흉내 내기 시작한 지점이라고 느껴졌습니다.
앞으로 기술이 더 발전할수록 딥러닝은 보이지 않는 곳에서 더 자연스럽게 우리 삶에 스며들 가능성이 큽니다. 그래서 “딥러닝이란 무엇인가”를 한 번쯤 제대로 이해해두는 건, 이제 선택이 아니라 기본 지식에 가까워지고 있다고 생각했습니다.